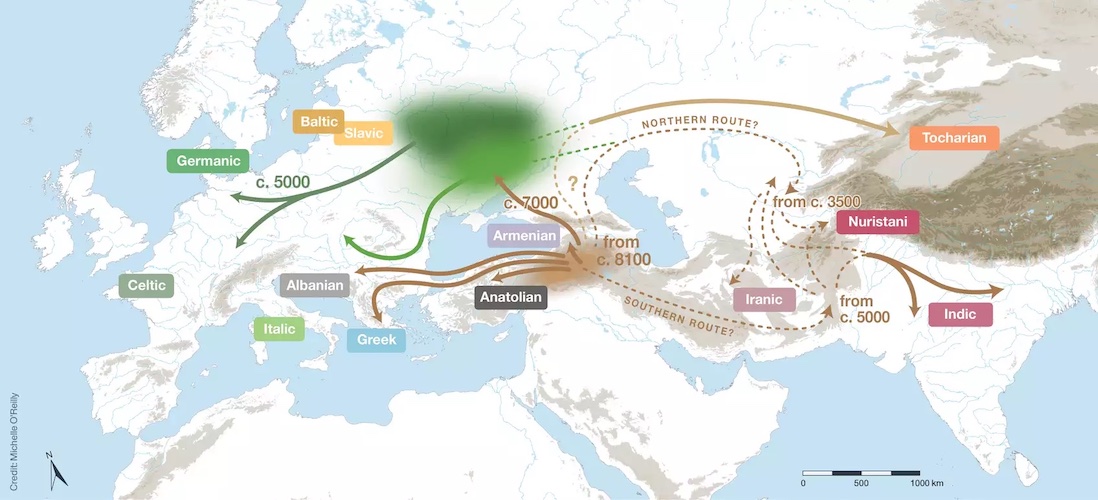
The language family began to diverge from around 8,100 years ago, out of a homeland immediately south of the Caucasus. One migration reached the Pontic-Caspian and Forest Steppe around 7,000 years ago, and from there subsequent migrations spread into parts of Europe around 5,000 years ago according to P. Heggarty et al., Science (2023)
A pair of new papers are out on the origins of the Indo-European languages, like previous papers by Russel Gray, the estimate of an 8,100 year origin for the language family is too old. The main problem is a misinterpretation of the genetic and anthropological data, especially related to the Anatolian languages. The notion that the Indo-European languages have a source in the Caucuses or in Anatolia or points south of it don't hold water.
As noted by a comment at Language Log:
[T]his article seems similar to the piece in Science with Quentin Atkinson from 2012, corrected in response to some of the criticism by linguists (eg. Romani has apparently been removed from the list of languages), but not citing the book by Pereltsvaig and Lewis which was the best single source for that criticism[.]
Atkinson and Gray are academic colleagues in New Zealand.
The Anatolian languages look diverged from the other Indo-European languages, and hence look old, because of language contact effects with substrate languages very different from those present in the formative periods of the other Indo-European languages.
Gray's models too heavily emphasize a hypothetical random mutation rate and greatly underestimate how much language change is due to language contact. If you are Iceland with very little language contact, you can still read 10th century Iceland texts today. If you are a language experiencing lots of language contract, like England, anything you read before the 15th century is incomprehensible.
There is no convincing historical, archaeological, or genetic evidence of any Indo-European presence in Anatolia much before 2000 BCE, despite the existence of literate cultures in that region at that time. But, there is strong archaeological and historical evidence of a migration of Indo-European people into Anatolia around 2000 BCE. There is no evidence of a steppe genetic signature in Anatolia on a large scale before then. There is also no relationship between the Indo-European languages and the languages that were present in the alleged region of their origin in the right time frame.
Likewise, there is no convincing archaeological or genetic evidence of an origin for the Indo-European languages in the Caucuses.
The front material of one of them is as follows:
Précis
An international team of linguists and geneticists led by researchers from the Max Planck Institute for Evolutionary Anthropology in Leipzig has achieved a significant breakthrough in our understanding of the origins of Indo-European, a family of languages spoken by nearly half of the world’s population.
Introduction
For over two hundred years, the origin of the Indo-European languages has been disputed. Two main theories have recently dominated this debate: the ‘Steppe’ hypothesis, which proposes an origin in the Pontic-Caspian Steppe around 6000 years ago, and the ‘Anatolian’ or ‘farming’ hypothesis, suggesting an older origin tied to early agriculture around 9000 years ago. Previous phylogenetic analyses of Indo-European languages have come to conflicting conclusions about the age of the family, due to the combined effects of inaccuracies and inconsistencies in the datasets they used and limitations in the way that phylogenetic methods analyzed ancient languages.
To solve these problems, researchers from the Department of Linguistic and Cultural Evolution at the Max Planck Institute for Evolutionary Anthropology assembled an international team of over 80 language specialists to construct a new dataset of core vocabulary from 161 Indo-European languages, including 52 ancient or historical languages. This more comprehensive and balanced sampling, combined with rigorous protocols for coding lexical data, rectified the problems in the datasets used by previous studies.
Indo-European estimated to be around 8100 years old
The team used recently developed ancestry-enabled Bayesian phylogenetic analysis to test whether ancient written languages, such as Classical Latin and Vedic Sanskrit, were the direct ancestors of modern Romance and Indic languages, respectively. Russell Gray, Head of the Department of Linguistic and Cultural Evolution and senior author of the study, emphasized the care they had taken to ensure that their inferences were robust. “Our chronology is robust across a wide range of alternative phylogenetic models and sensitivity analyses”, he stated. These analyses estimate the Indo-European family to be approximately 8100 years old, with five main branches already split off by around 7000 years ago.
These results are not entirely consistent with either the Steppe or the farming hypotheses. The first author of the study, Paul Heggarty, observed that “Recent ancient DNA data suggest that the Anatolian branch of Indo-European did not emerge from the Steppe, but from further south, in or near the northern arc of the Fertile Crescent — as the earliest source of the Indo-European family. Our language family tree topology, and our lineage split dates, point to other early branches that may also have spread directly from there, not through the Steppe.”
New insights from genetics and linguistics
The authors of the study therefore proposed a new hybrid hypothesis for the origin of the Indo-European languages, with an ultimate homeland south of the Caucasus and a subsequent branch northwards onto the Steppe, as a secondary homeland for some branches of Indo-European entering Europe with the later Yamnaya and Corded Ware-associated expansions. “Ancient DNA and language phylogenetics thus combine to suggest that the resolution to the 200-year-old Indo-European enigma lies in a hybrid of the farming and Steppe hypotheses”, remarked Gray.
Wolfgang Haak, a Group Leader in the Department of Archaeogenetics at the Max Planck Institute for Evolutionary Anthropology, summarizes the implications of the new study by stating, “Aside from a refined time estimate for the overall language tree, the tree topology and branching order are most critical for the alignment with key archaeological events and shifting ancestry patterns seen in the ancient human genome data. This is a huge step forward from the mutually exclusive, previous scenarios, towards a more plausible model that integrates archaeological, anthropological and genetic findings.”
The Supplemental Materials are here. The figure below is from the Supplemental Materials:
Fig. S6.1 Maximum Clade Credibility (MCC) tree for the tree distribution from Model M3. This MCC tree corresponds to the DensiTree in Fig. 2 in the main text, summarizing the posterior distribution of trees. Here, uncertainty in tree topology is represented by the posterior probability shown for each node. Any branch leading to a node with a posterior probability of less than 0.5 is shown as a dashed line. Branches that end before the right-hand margin represent non-modern languages, used here as date calibrations. Colors indicate the established clades of Indo-European, following the same color scheme as in the language map and DensiTree figure in the main text.
Section 7.7 of the Supplemental Materials notes that:
In our main analysis we apply no ancestry constraints, given the known objections to doing so, in particular to forcing ancient, written register languages to be direct ancestors of modern spoken languages. Nonetheless, a major previously published paper does apply such ancestry constraints (12), and reports a powerful effect in leading to much shallower estimates of the root depth of the Indo-European family.
Reference 12, which is a much more credible effort to address Indo-European origins is: W. Chang, C. Cathcart, D. Hall, A. Garrett, "Ancestry-constrained phylogenetic analysis supports the Indo-European steppe hypothesis." Language 91, 194–244 (2015) (link is to the pdf full text). It's abstract states:
The counterfactual conclusions of their model when failing to apply these constraints, noted in Section 7.7 for Latin to Romance languages, classical Armenian as an ancestor of modern Armenian, Mycenaean Greek as an ancestor of Ancient and New Testament Greek, and Old English as an ancestor of modern English, all seriously cast doubt on the soundness of the model.
Razib Khan has a lengthy commentary at his Gene Expression blog. He too casts doubt on the "Southern Arc" hypothesis that Indo-Europeans were present very early on in Anatolia and the Southern Caucuses:
We have some histories of the Middle Eastern Bronze Age. We know that the area of southwest Iran was dominated by the non-Indo-European Elamites as early as 3000 BC, and these people persisted down into the Common Era. Modern Armenia was dominated by non-Indo-European speaking Urartians after 1000 BC. This language is related to Hurrian, documented 4,000 years ago. Before the Indo-European Hittites ruled Hatti, the Hattians ruled Hatti. And the Hattians were not Indo-European. Judging by the obscure Eteocretan language that persisted into antiquity the Minoans were almost certainly not Indo-European speaking.
Around 1500 BC it is true the ruling elite of the Hurrians, the Mittani, seem to have had an Indo-Aryan connection, but they were also likely intrusive, and their emergence as mobile warriors suspiciously post-dates the development of the light war chariot and the domestic horse thousands of miles to the north several centuries earlier by the Sintashta. The Assyrian royal annals date the arrival of Persians to the 9th century BC, but the results in the paper imply that the Iranians were already present in the Zagros for thousands of years before this (the south Caucasus being the Indo-European ur-heimat ultimately, the Indo-Iranians moving south and east very early on from that region).
I’m focusing on the Middle East because there is a rich history of textual evidence starting in the third millennium BC. These results imply that Indo-European languages are in fact native to the northern Middle East, in the southern Caucasus. And yet assorted obscure languages like Gutian, Kassite and Kaska, are found where you might expect a stray Indo-European here and there. To me this is curious and weird. Further to the west, these results seem to imply that Greek was brought with Caucasus ancestry, but Minoan was likely not Indo-European. There are all these non-Indo-European languages attested in the textual record…and only a few Indo-European ones (Hittite being the first). . . .
This doesn’t mean the other models don’t have holes, the “Southern Arc” theory is pretty complicated too, and everything would have been “easier” if the Hittites had steppe ancestry, and they do not seem to.
The earliest historically attested appearance of the Hittites is around 2000 BCE in written communications from Akkadian merchants, and this is corroborated by the archaeological evidence. Steppe ancestry appears in Anatolia only after this date.
With respect to Tocharian he notes:
Tocharian languages were found in the northern and northeast regions of the Tarim basin. Historically, the southern rim of the basin was dominated by Iranian languages. It seems the most likely candidate for the people that gave rise to the Tocharian languages is the Afanasievo culture. The Afanasievo we now know were basically an eastern branch of the Yamnaya that show up in the Altai 3300 BC. This is 5,300 years BP. In the paper, the Tocharian split from other Indo-Europeans 5,400 to 8,600 years BP over a 95% confidence interval. The only way this makes sense to me is if there was deep linguistic structure within the Yamnaya despite overall genetic homogeneity maintained through mate exchange. In the text the authors seem to imply that the Tocharians are an early eastward migration, perhaps from the south Caucasus region. This does not align very well with the ancient DNA. The Afanasievo early on are replica copies of Yamnaya.
So, again, the linguistic hypothesis of the paper is out of synch with the archaeological and ancient DNA evidence. And there are no well documented examples in historical linguistics of societies that are otherwise as homogeneous and contiguous as the Yamnaya harboring this kind of deep linguistic substructure for thousands of years.
He also comments skeptically on other aspects of the paper:
One of the major points of this paper that contradicts some theories in historical linguistics is a rejection of the tentative connection between Balto-Slavic and Indo-Iranian. Genetically, the curious aspect of the two language families is that Y chromosomal haplogroup R1a is very frequent in both, but differentiated into two lineages that seem to have diverged 5,500-6,000 years ago. But there is more than just Y chromosomes here; over the past decade autosomal genome analyses show that many South Asians, in particular those in the northwest and upper caste populations are enriched for a minority ancestral component that resembles Eastern Europeans. We now know what happened due to ancient DNA: Genetic ancestry changes in Stone to Bronze Age transition in the East European plain. A branch of the Corded Ware Culture (CWC) migrated eastward, becoming the Fatyanovo Culture, then the Balanovo Culture, then the Abeshevo Culture, and finally the Sintashta Culture. The Sintashta seem to have given rise a group of societies known as Andronovo that are hypothesized to evolved into Iranians and Indo-Aryans.
The result here does away with all this. Rather than Indo-Aryan speech being brought by steppe pastoralists between 3,500 and 4,000 years ago, as genetics would imply, the Indo-Aryan speech was likely present during the Indus Valley Civilization. These results imply that Indo-Aryan arrived in India thousands of years before the intrusion of steppe pastoralists, and it was carried eastward by farmers from the Caucasus. The Vedas and Sanskrit then come down from the IVC. And yet strangely the Vedas do not depict a very complex society like the IVC, but a more simple agro-pastoralist one. And, the sacred language of the IVC people presumably, Sanskrit, was maintained in particular by a Brahmin priestly caste that is notable for having a very high fraction of steppe ancestry, that much arrived later.
Again, this linguistic model is simply wrong. The timing of the archaeological evidence and the ancient DNA is indisputable. The inferences that must be made from this evidence to reach historical linguistic conclusions are easy and small ones. But there is simply no narrative consistent with the paper linguistic first based model, which relies on extremely uncertain and ill documented assumptions about how languages evolve over time, that makes any sense.
Razib notes that there are also serious reasons to doubt the claimed timing of the divergence of European subfamilies of the Indo-European languages which archaeological and ancient DNA evidence point to taking place after Corded Ware Culture expansion into Europe:
A massive issue of this paper is that it makes a hash of a major phenomenon that we know between 3500 and 2500 BC, and that’s the spread of steppe-people in all directions, especially out of the Corded Ware complex.
The CWC are notable for having a major admixture of Globular Amphora Culture (GAC) Neolithic ancestry, about 25-35% of their genetics, and then spreading into all directions. As noted by the authors and other observers, ancient DNA suggests that Anatolian, Armenian, and perhaps Greek and Illyrian (Albanian), are exceptions to this, deriving directly from Yamnaya or pre-Yamnaya (in the case of Hittites) Indo-European people (remember, CWC is a mix of Yamnaya and GAC).
The genetics is very clear that a major wave of post-CWC people went into Asia, and south into the Indian subcontinent and Iran. The Y chromosomes imply this was male mediated, and post-CWC Y chromosomes are found in appreciable quantities as far south as Sri Lanka. But these data place this demographic migration far too late to have been the origin of Sanskrit, which is associated with Arya culture.
As Lazaridis points out on social media, the divergence of European language groups like Germanic, Celtic, Italic and Balto-Slavic also predates the CWC expansion westward. For example, Italic language split off in 3500 BC, 500 years earlier than the expansion of CWC into Eastern Europe, with a 95% lower-bound of 2200 BC, about when steppe ancestry shows up in the Italian peninsula according to ancient DNA. If the dates are true then it seems that the various Indo-European language groups were differentiated already very early on in the Yamnaya, and not later on through their expansion across Europe. In other words, this is a model of “ancient linguistic substructure.”
Rather than letting an unproven and highly uncertain linguistic evolution model set the parameters and try to shoehorn hard and precise archaeological, historical, and ancient DNA evidence into this model's timeline, we using the archaeological, historical, and ancient DNA evidence to calibrate and frame the parameter space of any linguistic evolution model.
We know that Tocharian split from other Indo-European languages around 3300 BCE. We know that Balto-Slavic and Indo-Iranian split around 3000 BCE to 2500 BCE. We know that the Indo-Aryan languages arrived in South Asia from Central Asia sometime after the collapse of the Harappan culture ca. 2500 BCE to 1500 BCE. We know that the European branches of the Indo-European languages began to differentiate sometime during and after the spread of the Corded Ware Culture in Europe between 3500 and 2500 BCE. We know that the Indo-European languages reach the Italian Peninsula around 2200 BCE. We know that the Anatolian languages arrived in Anatolia around 2200 BCE to 2000 BCE, and that Mycenean Greek arrived in the Aegean at around the same time.
If the linguistic model doesn't match these hard dates then the linguistic model is broken. And, the single biggest factor throwing off the linguistic model is the assumption that because Tocharian (which has little language contact as it expands and is probably the most conservative of the documented Indo-European languages relative to Proto-Indo-European because it had very little language contact) and the Anatolian languages (which had stronger and more diverged substrate influences). As I explain in a comment at Razib's blog post:
Razib, presumably out of politeness, lays the foundation but doesn’t reach the final punchline, which is that the linguistic model is seriously flawed, and that the narrative the flows from trying to shoehorn the linguistic model’s conclusions into the hard evidence from archaeological evidence, historical accounts, and ancient DNA is likewise just plain wrong. We should be using the hard, precisely dated and placed evidence to calibrate the linguistic model instead of the other way around, because the parameters and assumptions of the linguistic model are profoundly less certain in date and in place.
The single biggest driver of the problem with the linguistic model is the assumption that the Anatolian languages, because they are more diverged from the other Indo-European languages, are also the oldest. All other things being equal, that isn’t an unreasonable assumption, but all other things are not equal.
The Neolithic societies of Europe and South Asia in which Indo-European languages replaced pre-existing Neolithic languages were all in a state of abject collapse when the Indo-European language speaking steppe people swept in, so the pre-existing substrate languages had much less of an impact on the Indo-European languages in those places, than in Anatolia. Further, in Europe, all of the substrate Neolithic first farmer languages were part of a single macro-linguistic family derived from the languages of the Western Anatolian source for the first farmers, possible with one major division between the LBK wave along the Danube and other inland river systems, and a Cardial Pottery wave skirting to Northern Mediterranean coast. Some of what we attribute to Proto-Indo-European or to a very basil split on the European side of the Indo-European languages may actually be shared substrate influences from similar languages in this European Neolithic language family (systemically understating the impact of language contact with these languages).
Likewise, in the East, the Indo-Iranian languages probably shared a common Harappan language family substrate.
In contrast, the Anatolian Indo-European languages saw their speakers, especially the Hittites, conquering a much more sophisticated Eneolithic/Early Bronze Age Hattic society whose linguistic predispositions were not so easily swept aside. Even after Hittite became the dominant secular language of the Hittite empire, the non-Indo-European Hattic language survived as a liturgical language akin to church Latin, post-Sumer Sumerian, and ancient Hebrew, for another thousand years, something that happened nowhere else in the Indo-European linguistic region. And, the languages of Anatolia and the Caucasian and Iranian highlands by the metal ages, were very different from the languages of the Western Anatolian Neolithic ancestors of Europe’s first farmers.
The Anatolian languages are more diverged from other Indo-European languages not because they are older, but because there was a stronger substrate influence and the substrate that was the source of the influence was much different. You can read and hear the extent of the influence by comparing Hittite names and words and sentences to their Hattic counterparts (preserved well in large volumes of royal record keeping) and their Minoan counterparts (preserved in phonetic transcriptions in Egyptian texts and what can be guessed at from Linear B writing).
Tocharian seems older than it really is for the opposite reason. Unlike every single other known Indo-European language, it had little or no substrate influence as it expanded into thinly populated regions en route to and in the Tarim Basin. It is probably the most conservative linguistically, kept pure from reduced contract on the frontier in much the same way that Icelandic on the frontier is the closest Germanic language to Old Norse, the same way that the Appalachian dialect of English is the closest the English dialect of Shakespeare as it was isolated on the frontier, and the same way that the Spanish dialect spoken by multigenerational natives of Southern Colorado and New Mexico are the only dialects of Spanish that retain some of its Spanish colonial era archaic words and grammatical constructions in living languages. The shared substrate influences of Western Anatolian Neolithic and Harappan language families on languages that were not Anatolian or Tocharian are absent in Tocharian and that is why it seems more diverged.
New Zealand academic Russell Gray in this paper is repeating the sins of his fellow New Zealander Quentin Atkinson in his 2012 paper in Science. Later work by Atkinson recognized that increasing the amount of language evolution attributed to language contract and decreasing the amount of language evolution attributed to random mutation produced more reasonable estimates of the time depths of the various Indo-European languages. But these lessons were lost on the authors of the current paper.
The authors of the current paper, instead, forge an utterly unconvincing “Southern Arc” narrative that has to be riddled with exceptions to principles and inferences about ancient DNA markers of Indo-European languages, about the lack of a reason for archaeologically and genetically homogeneous and geographically compact societies to have deep linguistic divides. They remove the climate and other motives of expansion too.
Another comment seen elsewhere on the paper:
They have a systematic error of branch scaling which elongates branches with excessive borrowing (which is especially typical for Indic languages) or have limited knowledge of synonym pairs representing meanings in their dataset (which is common for many ancient languages). Both problems stem from the same computational simplification. Namely, they treat each cognate responsible for the given meaning as an independent binary value (present or absent) while in reality, presence or absence of synonyms for a given meaning are negatively correlated.
Basically in the languages where coevolving synonyms are well attested, a gain or a loss of a synonym will generally have a change value of 1 (1,1 -> 1,0 or vice versa). But in languages with external borrowing or with unknown synonym pairs, any such change would count as 2 (loss of the original cognate plus gain of a new one).
This scaling problem would have inferred even older split dates have it not been artificially limited by setting the upper bound for the age at 10,000 years. In one of the sensitivity analyses they removed this upper bound and ended up with estimates as old as 11 kya.
There is also an important linguistic consideration for the Northern route and against the South Caucasus urheimat, and it is borrowings from IE to neighboring languages. The oldest layer of IE-derived words in the Finno-Ugric languages is thought to be related to proto-Iranian and dated to ~Sintashta epoch in the Ural Mountains. Conversely, Gamkrelidze and Ivanov assembled a great collection of potentially IE-derived words in Kartvelian and Semitic languages but nothing there is convincingly older than Mitanni age.
This issue is discussed in Section 7.10 of the Supplemental Materials which notes that:
Our multistate model produces root age estimates distinctly younger (by 2057 years, or 25.1%) than any produced by the covarion model: 6153 BP (4926–7884 BP). In tree topology, the multistate results show a similar lack of resolution at basal nodes of the phylogeny, although there remains strong support for a European clade of Germanic, Celtic and Italic, and for a nesting of Nuristani within Indic.
The chart with the difference in methodology (Figure 7.10.2) is:
A criticism of the paper at a Substack page can be found here. It opens with this framing:
Advances in genetics, linguistics, and archaeology have eliminated all but two theories of the Indo-European urheimat from consideration. The first theory is Steppe Theory – that the speakers of proto-Indo-European – the last stage of the language prior to its fragmentation into multiple branches – lived on the Pontic Steppe in what is now eastern Ukraine and southern Russia some 5,000 to 6,000 years ago. The second theory is Southern Arc Theory – that proto-Indo-European was spoken within the same time frame, but at an unspecified point between the southeastern Balkans and Azerbaijan.
I haven’t made up my mind on which theory I believe, so I will do my best to lay out their cases and problems. It is notable that they differ little in their understanding of the Bronze Age (roughly 3300 BC and after). Their understandings differ instead in the even more temporally distant Copper Age (roughly 4500 to 3300 BC). . . .
Most of the Indo-European languages are believed to have fragmented into branches such as Indo-Iranian, Balto-Slavic, Italo-Celtic, Graeco-Armenian, or Germanic during the third millennium BC. However, there were two exceptions. The first is the Tocharian branch, attested in the Tarim Basin of what is now Xinjiang, China in the 1st millennium AD.
The second is the Anatolian branch - Hittite, Luwian, and Palaic. The Anatolian languages are attested in the second millennium BC in Anatolia – what is now Asiatic Turkey. Both the Anatolian and Tocharian branches appear to have split from the other Indo-European languages prior to 3000 BC – Anatolian possibly even before 4000 BC.
The Anatolian languages have a number of odd features that set them apart from the other early Indo-European languages. They only have a present and a past tense, while other Indo-European languages have as many as six. They lacked a dual, and they had only an animate and neuter case unlike the other Indo-European languages. Additionally, the Hittite (an Anatolian language) word for wheel is not an Indo-European cognate. Wheels were invented and spread in the second half of the fourth millennium BC. As such, the linguistic and archaeological evidence implies that the Anatolian languages diverged from the main Indo-European languages prior to 3500 BC - centuries before the others.
[I note, editorially, that grammatical simplification is a phenomena commonly seen in bilingual communities with lots of language learners as the new language is formed, so the lost of 1-4 temporal tenses and a dual case is consistent with a strong substrate influence, as would a tendency of language learners who speak a substrate language to retain some core vocabulary word's from the substrate language, like "wheel". We know that the "wheel" technology originated on the steppe rather than in Anatolia.]
Theories of Indo-European origins must account for the existence of the Anatolian languages and their early split from the rest of the language family. The Steppe theory and the Southern Arc theory address it in different ways.
The Steppe theory argues that the Anatolian languages are the product of a very early migration out of the steppe. Riding horses from the Indo-European urheimat in what is now eastern Ukraine, the earliest Anatolian speakers were rich in steppe ancestry, split from their cousins, and invaded the eastern Balkans and Hungary in the late 5th millennium BC. There, they created the Suvorovo and related cultures, spreading the ancestors of the Anatolian languages. The Anatolian-speaking Suvorovo people migrated south centuries later, eventually becoming part of the Ezero Culture in late 4th millennium BC Bulgaria and Thrace. Then, during the chaotic period of the 34th century BC (which, characterized by the invention of the sail, also saw the unification of Egypt and the massive Minoan invasion of Greece), they migrated into northwestern Anatolia. There, the Anatolian languages fragmented. The Luwians remained in western Anatolia, while another group of speakers conquered central Anatolia in the early 2nd millennium and formed the Hittite realm. At each step of the path, the original Steppe ancestry was diluted to the point where it was barely detectable in Anatolia.
[Of course, I am a steppe origin advocate who rejects this narrative.]
The Southern Arc theory looks at the Anatolian languages differently. The lack of steppe ancestry in over a hundred ancient DNA samples from the Neolithic to Classical Ages shows that steppe penetrations into Anatolia were too minor and too late to have introduced the Anatolian languages to the region. For instance, Classical Age DNA finds in the city of Gordion are only about 4% Steppe in ancestry - even though the city had been ruled by four separate Indo-European groups. Additionally, the steppe ancestry in the Balkans present in the 3rd millennium BC is entirely from the migrations that occurred earlier that millennium. There is no evidence for any pre-3300 BC steppe-ancestry-rich Indo-European groups in the Balkans surviving to a point where they could have potentially migrated to Anatolia.
[This is an important reason why I argue that the Anatolian languages arrived in Anatolia only in about 2000 BCE.]
The Southern Arc offers another explanation for the Anatolian languages. Instead of originating on the steppe, it argues that the Anatolian languages are the remnants of the Indo-European languages that remained in their urheimat in the Southern Arc - a region from the southern Balkans to Azerbaijan - prior to the language ancestral to all of the other branches of Indo-European spreading north across the Caucasus or Black Sea to the steppe. Increases in Caucasian Hunter-Gatherer and Anatolian and Levantine Farmer ancestry in the steppe population at various points between 4500 and 3300 BC could have been the vector that spread the Indo-European languages from the Caucasus to the steppe peoples. After spreading to the steppe, the non-Anatolian Indo-European languages would have been spread across Europe, Central Asia, Iran, and India.
The Southern Arc theory is a great deal less specific than the Steppe theory, and will need to be fleshed out more. It is possible that the Chaff Faced Ware peoples of the southern Caucasus diffused across the Caucasus in the mid-5th millennium, bringing the Indo-European languages with them. It is also possible that the mighty Maykop people, known to have had cultural contacts with the steppe peoples, could have spread the Indo-European languages to their trading partners as a trade language.
In my opinion, the most likely candidates for introducing the Indo-European languages to the steppe peoples (assuming that the Southern Arc Theory is true) are the mysterious pre-Maykop peoples of the North Caucasus. The pre-Maykop peoples of the North Caucasus interacted with the peoples of the Danube Valley across the Black Sea as well as with the peoples of the steppe in the late 5th millennium BC. Copper from the Carpathians made it to the North Caucasus while boar’s tusk pendants and mace heads from the Caucasus made it to the Danube. However, little is known about them, and it is unlikely that much ever will be known about them. They were apparently destroyed by the Maykop people, and likely have no descendants.
There is a third theory, almost invariably promoted by linguists, which argues for a specifically Anatolian origin of the Indo-European languages. While on the surface it resembles the Southern Arc theory, it’s timing is very different. Rather than a proto-Indo-European language that splits between Anatolian and standard Indo-European in the late 5th millennium BC, it instead places the divergence of the Indo-European languages in the mid-7th millennium BC. It associates the spread of the Indo-European languages with the spread of farming from Anatolia, with the Anatolian Farmers and their European cousins, the Early European Farmers.
The Substack article goes on to debunk this theory.
Another error in the new paper is that it claims that no southward migration of Steppe_MLBA pastoralists is attested by aDNA from BMAC sites in 2300-1700 BCE by citing Narasimhan et al. 2019 stating:
But, the paper cited actually concludes that Steppe_MLBA pastoralists migrated southward from 2100-1700 BCE. The cited paper actually says in the pertinent part:
This kind of basic misstatement of the conclusion of researchers who are relied upon for a thesis in a leading peer reviewed scientific journal is highly unimpressive and just plain sloppy.
Eurogenes adds criticism here.